

MY SQL의 쿼리 성능을 최적화 하려면 매우 많은 부분을 생각해야합니다. 단순히 인덱싱만 한다고 해서 해결되는게 아닐경우도 있는데요. 그런 최적화를 위해서 기본적으로 SELECT 문의 성능을 확인하는 EXPLAIN을 사용해야합니다.
우선은 EXPAIN의 기초는 나중에하고 일단 EXPLAIN을 하게되면 나오는 스키마 중에 성능, 속도를 가장 밀접하게 알려주는 TYPE의 종류에 대해 알아보겠습니다.
물론 TPYE 뿐만아니라 다른 컬럼과 무조건 종합적으로 분석해야 합니다.
다른 컬럼들에 대한 설명은 추후에하고 우선은 TYPE 먼저 분석하겠습니다.
우선 TYPE은 MYSQL데이터 베이스가 해당 테이블의 레코드에 어떤 방식으로 접근 하였는가? 이것을 나타내는 컬럼입니다.
즉 해당 데이터를 어떠한 방식으로 검색했는지 조회했는지를 알수 있습니다.
그리고 그 방식들간의 성능, 속도간의 차이가 있는데 성능의 차이는 아래와 같습니다.
환경은 MYSQL 8.0이상 버젼입니다.
TPYE 값의 의미 및 성능
| 순위 | TYPE 값 | 성능 수준 | 주요 특징 |
| 1 | system | 최상 (Ideal) |
단 0개 또는 1개의 레코드 접근 (매우 드뭄)
|
| 2 | const | 최상 (Ideal) |
PK 또는 UNIQUE 키로 1개의 행에 상수처럼 즉시 접근
|
| 3 | eq_ref | 최상 (Ideal) |
조인에서 PK/UNIQUE 키로 정확히 1개의 행 접근
|
| 4 | ref | 매우 좋음 (Excellent) |
일반 인덱스로 일치하는 여러 행 접근
|
| 5 | fulltext | 좋음 (Good) |
FULLTEXT 인덱스 검색
|
| 6 | ref_or_null | 양호 (Good) |
ref + NULL 값 포함 검색
|
| 7 | index_merge | 양호 (Good) |
여러 인덱스 검색 결과를 병합하여 사용
|
| 8 | unique_subquery | 양호 (Good) |
IN 절 내 UNIQUE 서브쿼리 최적화
|
| 9 | index_subquery | 양호 (Good) |
IN 절 내 일반 서브쿼리 처리
|
| 10 | range | 주의 필요 (Fair) |
인덱스를 사용한 범위 검색 (<, >, BETWEEN, IN)
|
| 11 | index | 느림 (Poor) |
인덱스 전체를 처음부터 끝까지 스캔
|
| 12 | ALL | 최악 (Worst) |
테이블 전체를 스캔 (Full Table Scan)
|
이렇게 위의 순서대로 성능이 있는데 이중에 가장 기본적으로 성능 최적화라고 한다면 최소 ref 까지 성능을 만들고
가장 이상적인 것은 const, eq_ref 입니다.
- 이상적: const, eq_ref
- 허용 가능: ref, range
그럼 이제 하나하나씩 어떤 상황일때 해당 값이 뜨는지 예시를 보면서 확인 해보겠습니다.
Case.1 system(시스템 테이블)
EXPLAIN SELECT * FROM (
SELECT 1 AS id, 'test' AS value
) AS derived_table;
가장 드물고 특수한 경우
- 옵티마이저가 행 개수를 알고 있음
- 테이블에 최대 1개의 행
위의 서브쿼리처럼 테이블 조회시 disk/io가 없거나 옵티마이저가 행을 알고 있는경우에 system이 나옵니다. 실제 서비스테이블에서는 system이 나올 경우가 매우 드뭅니다.
Case.2 const(상수 비교)
-- 상황: PK 또는 UNIQUE 키로 정확한 값 비교
CREATE TABLE users_test (
id INT PRIMARY KEY,
name VARCHAR(50),
email VARCHAR(100) UNIQUE
);
INSERT INTO users_test VALUES (100, 'John', 'test@test.com');
-- Case 2-1: PK로 정확한 값
EXPLAIN SELECT * FROM users_test WHERE id = 100;
-- type: const ✅
-- Case 2-2: UNIQUE 키로 정확한 값
EXPLAIN SELECT * FROM users_test WHERE email = 'test@test.com';
-- type: const ✅
-- Case 2-3: 상수 비교
EXPLAIN SELECT * FROM users_test WHERE id = 100 AND name = 'John';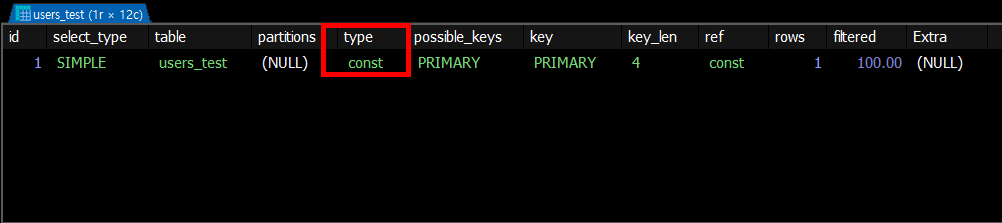
고정된 값으로 정확히 1개 행
- PK 또는 UNIQUE 인덱스
- 상수(고정값) 비교 (= 사용)
- 결과: 항상 최대 1개 행
const는 PK 또는 UNIQUE 인덱스 전체를 사용해서 결과가 항상 최대 1개 행으로 보장될 때만 const가 나옵니다.
Case.3 eq_ref(조인 1대1)
-- eq_ref 실제 발생 예시
CREATE TABLE users_test (
id INT PRIMARY KEY,
name VARCHAR(50)
);
CREATE TABLE user_profiles (
user_id INT PRIMARY KEY,
bio TEXT,
FOREIGN KEY (user_id) REFERENCES users_test(id)
);
INSERT INTO users_test VALUES
(1, 'John'),
(2, 'Jane'),
(3, 'Bob'),
(4, 'Alice'),
(5, 'David');
INSERT INTO user_profiles VALUES
(1, 'Dev'),
(2, 'Designer'),
(3, 'Manager'),
(4, 'QA'),
(5, 'PM');
EXPLAIN SELECT u.name, up.bio
FROM users_test u
INNER JOIN user_profiles up ON u.id = up.user_id
WHERE u.id IN (1, 2);
EXPLAIN SELECT u.name, up.bio
FROM users_test u
INNER JOIN user_profiles up ON u.id = up.user_id;
조인(JOIN)에서 PK나 UNIQUE 키로 정확히 하나의 행을 찾아냄
- JOIN 조건이 PK/UNIQUE 키
- 오른쪽 테이블에서 최대 1개 행 매칭
- 1대1 관계 보장
eq_ref는 두개 이상의 테이블이 조인 될때만 나타나며 단일 테이블 조회에선 나올수 없습니다.
또 조인하는 두번재 테이블에서 pk나 유니크 키 not null 인덱스가 지정되어야합니다.
그리고 조인시 첫 테이블과 두번재 테이블의 pk를 비교하여야 합니다.
위 조건이 결합하면 첫테이블에서 한 행씩 읽을때마다 두번째 테이블에서도 정확하게 일치하는 행만 찾을수 있다 확신합니다.
Case.4 ref(일반 인덱스)
CREATE TABLE products (
id INT PRIMARY KEY,
category_id INT,
name VARCHAR(100),
price INT,
INDEX idx_category (category_id) -- 일반 인덱스
);
INSERT INTO products VALUES
(1, 1, 'Laptop', 1000),
(2, 1, 'Mouse', 20),
(3, 2, 'Monitor', 300),
(4, 1, 'Keyboard', 50);
-- ref 발생 (여러 행)
EXPLAIN SELECT * FROM products WHERE category_id = 1;
일반 인덱스로 일치하는 여러 행 접근
- 일반 인덱스 사용 (PK/UNIQUE 아님)
- 복합 인덱스의 일부만 사용
- 여러 행 가능
where 에서 pk나 unique가 아닌 일반 인덱스를 조건으로 비교할 대 나타납니다. 또한 복합인덱스 중 일부만을 조건으로 사용할때 나타나고 조인에서 일반 인덱스를 사용할때 나타납니다.
eq_ref는 항상 1개행이 보장되고 ref 는 1개이상 여러행이 보장된다는 점이다.
Case.5 fullText(풀텍스트)
CREATE TABLE articles (
id INT PRIMARY KEY,
title VARCHAR(200),
content TEXT,
FULLTEXT INDEX ft_content (content) -- FULLTEXT 인덱스
);
INSERT INTO articles VALUES
(1, 'MySQL Guide', 'MySQL is a relational database'),
(2, 'SQL Tutorial', 'Learn SQL with examples'),
(3, 'Database Design', 'Proper database design principles');
-- fulltext 검색
EXPLAIN SELECT * FROM articles
WHERE MATCH(content) AGAINST('database' IN BOOLEAN MODE);
FULLTEXT 인덱스로 자연어 검색
- FULLTEXT 인덱스 존재
- MATCH() AGAINST() 연산자 사용
- 자연어 텍스트 검색
- Boolean 모드 또는 자연어 모드
대량의 텍스트 데이터에서 단어 기반의 검색 및 관련성 순위 지정을 위해 설계되었습니다. 타입은 특정 유형의 검색(전문 검색)에 최적화된 접근 방식이기 때문에, 일반적인 쿼리 성능 지표로 판단하기보다는 그냥 올바르게 해당 인덱스가 작동하는 지 확인 하면됩니다.
Case.6 ref_or_null
-- NULL 가능한 인덱스 컬럼
CREATE TABLE employees (
id INT PRIMARY KEY,
manager_id INT,
INDEX idx_manager (manager_id) -- NULL 가능
);
-- ref_or_null
EXPLAIN SELECT * FROM employees
WHERE manager_id = 1 OR manager_id IS NULL;
-- type: ref_or_null
인덱스 검색과 더불어 NULL 값까지 함께 검색.
- 인덱스 컬럼이 NULL을 허용
- = 동등 비교 또는 IS NULL 조건
- OR로 연결된 NULL 검색
- 인덱스로 NULL과 값을 동시에 검색
기본적으로 ref 조건을 만족하면서 추가적으로 OR IS NULL 조건이 붙게되면 발동합니다. 인덱스를 통해 일치하는 레코드를 먼저 찾은 다음에 null 이 포함된 레코드까지 추가적으로 검색하게 되는 동작입니다.
Case.7 index_merge
CREATE TABLE `master_data` (
-- PK를 구성하는 필수 식별자 컬럼
`key_id_a` VARCHAR(12) NOT NULL COMMENT '데이터 마스터 키 A',
`key_id_b` VARCHAR(20) NOT NULL COMMENT '데이터 마스터 키 B',
-- 검색 조건으로 사용될 독립된 인덱스 컬럼
`col_a` VARCHAR(80) DEFAULT '' COMMENT '검색 필드 A (예: 도로명)',
`col_b` VARCHAR(20) DEFAULT '' COMMENT '검색 필드 B (예: 시도명)',
-- 기타 정보 컬럼
`col_c` VARCHAR(20) DEFAULT '' COMMENT '추가 정보 필드 C',
`col_d` VARCHAR(20) DEFAULT '' COMMENT '추가 정보 필드 D',
`is_active` VARCHAR(3) DEFAULT '' COMMENT '사용 여부 플래그',
-- 기본 키 (Primary Key)
PRIMARY KEY (`key_id_a`, `key_id_b`) USING BTREE,
-- 💡 INDEX_MERGE 예시를 위한 독립 인덱스 💡
INDEX `idx_col_a` (`col_a`) USING BTREE,
INDEX `idx_col_b` (`col_b`) USING BTREE
-- 복합 인덱스 (기존 테이블의 복합 인덱스는 INDEX_MERGE 유도를 위해 제거했습니다.)
)
COMMENT='INDEX_MERGE 테스트용 마스터 데이터 테이블'
COLLATE='utf8mb4_0900_ai_ci'
ENGINE=InnoDB;
EXPLAIN SELECT * FROM master_data
WHERE col_a = '특정_값_A' OR col_b = '특정_값_B';
두 개의 독립된 단일 컬럼 인덱스(idx_col_a, idx_col_b)를 동시에 사용.
- 중복 인덱스 존재
- 또는 OR/AND 조건에서 여러 인덱스 활용 가능
- MySQL이 여러 인덱스의 교집합/합집합 계산
옵티마이저가 풀스캔 (ALL) 대신 인덱스 두개를 스캔하여 결과를 합치는 방식이 더 빠르다고 판단할 때 입니다. 일반적으로 비효율적인 방식이므로 중복인덱스를 조건을 하지말거나 적절한 인덱스를 재설정하는 작업이 필요합니다.
Extra의 Using union(...)을 보면 어떤 인덱스가 합쳐지는지 나옵니다.
Case.8 unique_subquery
CREATE TABLE employees (
id INT PRIMARY KEY,
name VARCHAR(100),
dept_id INT
);
-- 현재 세션
SET SESSION optimizer_switch='semijoin=off';
EXPLAIN SELECT * FROM employees
WHERE dept_id IN (SELECT id FROM departments);
메인 쿼리의 WHERE 절에 col IN (서브쿼리) 형태가 사용되어야 합며 이때 고유 인덱스 컬럼이 반환되어야 합니다.
- IN 서브쿼리에서 고유 인덱스(pk,unique,unique not null)를 조회
MySQL 옵티마이저가 서브쿼리 결과가 반드시 중복되지 않는 고유한 값의 집합임을 확신할 수 있을 때 이 타입이 선택됩니다.
Case.9 index_subquery
서브쿼리가 일반 인덱스 컬럼을 반환하거나, UNIQUE 인덱스라도 NULL을 허용할 때.
- IN 서브쿼리에서 일반 인덱스(pk,unique,unique not null)를 조회
Case.10 range(범위)
CREATE TABLE `users_test` (
`id` INT(10) NOT NULL,
`name` VARCHAR(50) NULL DEFAULT NULL COLLATE 'utf8mb4_0900_ai_ci',
`date` DATE NULL DEFAULT NULL,
PRIMARY KEY (`id`) USING BTREE,
INDEX `date` (`date`) USING BTREE
)
COLLATE='utf8mb4_0900_ai_ci'
ENGINE=InnoDB
;
EXPLAIN SELECT * FROM users_test WHERE DATE BETWEEN '2025-10-01' AND '2025-10-28'

인덱스를 사용하여 특정 범위 내의 행을 찾아냄 (<, >, BETWEEN,LIKE%).
- 범위 검색 조건 (BETWEEN, IN, >, <, >=, <=, LIKE% )
- 인덱스 활용 가능
- 여러 행 반환
인덱스가 걸린 컬럼에 다음과 같은 범위 연산자 (BETWEEN, IN, >, <, >=, <= ,LIKE의 경우 % 가 있어야함) 가 사용될 때 range 타입이 나타납니다. ALL처럼 모든 범위를 읽진 않지만 그래도 여러개의 행을 읽기 때문에 범위가 넓을수록 성능은 저하 됩니다.
Case.11 index(인덱스)
INDEX 타입은 MySQL이 인덱스 파일 전체를 순서대로 스캔해야 한다고 판단했을 때 발생하는 접근 방식입니다.
- WHERE 절 조건 없이 **ORDER BY**나 GROUP BY 절에 인덱스 컬럼을 사용하여 정렬
- SELECT 절에서 요구하는 모든 컬럼이 인덱스에 포함되어 있어(커버링 인덱스), 데이터 파일에 접근할 필요가 없을 때 인덱스 전체 스캔이 선택
- 이 인덱스가 정렬 순서대로 이미 저장되어 있기 때문에, 인덱스 전체를 읽어 별도의 정렬(filesort) 작업 없이 순서를 제공
Case.12 ALL(전체)
EXPLAIN SELECT * FROM orders
ALL 타입은 MySQL이 테이블의 모든 행을 읽어야 한다고 판단했을 때 발생하는 가장 비효율적인 접근 방식입니다
- 조건문 인덱스 미사용
- 옵티마이저가 테이블의 모든 행을 읽는 비용이 인덱스를 검색하고 데이터를 찾는 복잡한 과정보다 더 저렴하다고 판단할 때
- WHERE 절 조건 자체가 없음
조건이 걸려있고 해당 조건 컬럼에 인덱싱이 되어있는데도 all이 뜬다면 해당 인덱스를 타는것 보다 풀스캔을 하는게 옵티마이저가 더 낫다고 판단하는 경우입니다.
위의 케이스나 설명을 참고해서 현재 사용하고 있는 쿼리들의 속도가 all 이나 index 이면 튜닝이 필요하고 그게 아니더라도 ref 의 이상의 속도가 안나온다면 쿼리튜닝을 한번 고려해도 괜찮습니다.
단 해당 type만 가지고 튜닝을 하는것이 아니라 여러가지 상황을 조합해서 확인한 다음 다음 컬럼은 참고만하여 튜닝하는것이 가장 적절합니다.
'DB > Mysql' 카테고리의 다른 글
| MySQL 운영 DB에서 안전하게 트리거 우회하기 (내 세션만 일시정지하는 법) (1) | 2025.12.19 |
|---|---|
| MySQL: 이모지 삽입 시 Incorrect string value 오류 해결 (0) | 2025.11.17 |
| MY SQL RECORD LOCK PROCESS KILL 레코드 행락 킬하기 (0) | 2024.07.17 |
| MY SQL 데이터베이스에서 특정 컬럼명 포함된 테이블 찾는 방법 (0) | 2024.04.14 |
| MySQL 기본 인코딩 UTF-8설정하기 (0) | 2023.12.25 |