

집에서 개인프로젝트나 간단한 데모 테스트 db를 사용하고 싶고 로컬환경에서만 작업하고 싶지않은 분들을 위해서
가성비 끝판왕급 무료라고 생각할수 없는 수준의 클라우드 db를 추천해드리려고 합니다.
소개
NeonDB는 오픈소스 PostgreSQL을 기반으로 하되, 스토리지 엔진을 클라우드 환경에 맞게 밑바닥부터 재설계한 데이터베이스입니다.
가장 큰 특징은 '컴퓨팅(Compute)과 스토리지(Storage)의 완전한 분리'입니다. 기존 DB가 하나의 서버 안에 CPU, 메모리, 디스크를 묶어두었다면, Neon은 이들을 네트워크로 분리하여 각자 독립적으로 스케일링할 수 있게 만들었습니다.
가격정책 및 스펙
neonDB의 가격은 free와 launch sacle이 있는데 여기서 fee만 사용해도 일반적인 사이드 프로젝트나 개인 프로젝트 소규모 테스트 프로젝트로써는 손색이 없을정도의 스펙의 DB를 제공해줍니다.
아래 각 plan의 스펙을 보게되면 아래와 같습니다.
Free Plan
- 프로젝트 개수 100개
- 컴퓨팅비용 월 100시간 (프로젝트당)
- 프로젝트당 스토리지 500mb
- 하드웨어 사양 2cu 최대 8gb ram
Launch (스타트업용)
- 초기 서비스 출시 및 사용자 유입 단계에 적합
- 프로젝트 개수: 100개
- 월 기본료: $0 (No monthly minimum, 쓴 만큼만 냄)
- 컴퓨팅 비용: $0.106 / CU-hour (약 150원/시간)
- Scale-to-Zero(미사용 시 정지) 설정 시 비용 절감 가능
- 스토리지 비용: $0.35 / GB-month (약 500원/GB)
- 하드웨어 사양: 최대 16 CU (64 GB RAM) 까지 오토스케일링
- 백업/복구: 7일간의 데이터 시점 복구(PITR) 지원
- 모니터링: 3일간의 로그/지표 보관
Usage-based Scale Plan (엔터프라이즈급)
- 안정적인 고수익이 발생하고, 보안과 무중단 운영이 필수일 때
- 프로젝트 개수: 1,000+개
- 월 기본료: $0 (No monthly minimum)
- 컴퓨팅 비용: $0.222 / CU-hour (약 320원/시간, 성능 보장형)
- 스토리지 비용: $0.35 / GB-month (Launch와 동일)
- 하드웨어 사양: 최대 56 CU (224 GB RAM) 까지 오토스케일링
- 백업/복구: 30일간의 데이터 시점 복구(PITR) 지원
- 보안/네트워크: Private Network (VPC), IP 화이트리스트, SOC 2 / HIPAA 인증 지원
- SLA(가동률): 99.95% 보장 (다운타임 시 보상)

실행해보기
1.접속
아래 링크에 접속을 해줍니다.
Neon Serverless Postgres — Ship faster
The database you love, on a serverless platform designed to help you build reliable and scalable applications faster.
neon.com

2.대시보드
위의 화면에서 로그인을 하게 되면 아래와 같은 화면이 나오게 됩니다.

위의 화면에서 보다싶이 현재 사용된 자원의 양을 표기해줍니다. 위 이미지는 제가 실제로 한달동안 사용한 데이터베이스의 사용량인데 의미는 아래와 같습니다.
1. Compute: 8.08 CU-hrs (컴퓨팅 사용량)
의미: "서버 엔진을 돌린 총 시간 × 힘(Power)"입니다.
해석: 이번 달에 총 8.08 CU-시간만큼 엔진을 썼습니다.
Free Plan은 월 100 CU-hrs까지 무료입니다.
현재 상태: 100시간 중 약 8% 사용했습니다. (아직 널널함)
팁: 사이드 프로젝트는 Scale-to-Zero 덕분에 이 숫자가 아주 천천히 올라갑니다.
2. Storage: 0.14 GB (스토리지 사용량)
의미: "실제로 저장된 데이터의 크기"입니다.
해석: 현재 약 140MB 정도의 데이터가 저장되어 있습니다.
Free Plan은 0.5 GB (500MB)까지 무료입니다.
현재 상태: 500MB 중 약 28% 사용했습니다.
팁: 텍스트 데이터 위주라면 500MB는 꽤 많은 양입니다.
3. History: 0 GB (백업 저장량)
의미: "과거로 되돌리기 위해 저장해둔 변경 기록(WAL)"의 용량입니다.
해석: 현재 복구용 데이터가 거의 쌓이지 않았습니다. (0에 가까움)
Free Plan은 1 GB 또는 6시간 분량까지 무료입니다.
팁: 대량의 데이터 업데이트(Update/Delete)를 자주 하지 않으면 이 수치는 낮게 유지됩니다.
4. Network transfer: 0.08 GB (네트워크 전송량)
의미: "DB에서 바깥으로 보낸 데이터 양(Egress)"입니다.
해석: 약 80MB의 데이터를 조회(Select)해서 가져갔습니다.
Free Plan은 월 5 GB까지 무료입니다.
현재 상태: 5GB는 엄청난 사용량이 아니면 사이드프로젝트단계에선 다 사용할수 없을 정도로 넉넉니다. (매우 여유로움)
3.프로젝트 생성

프로젝트는 aws와 azure를 선택할수 있으며 각각의 이름을 지정하고 postgres 데이터베이스의 버젼까지 지정할수 있습니다.
그리고 리젼은 한국이랑 제일 가까운 아시아 리젼인 싱가포르를 선택하면 됩니다.
4.프로젝트 대시보드
생성을 하면 아래와 같이 프로젝트 대시보드가 나타납니다.
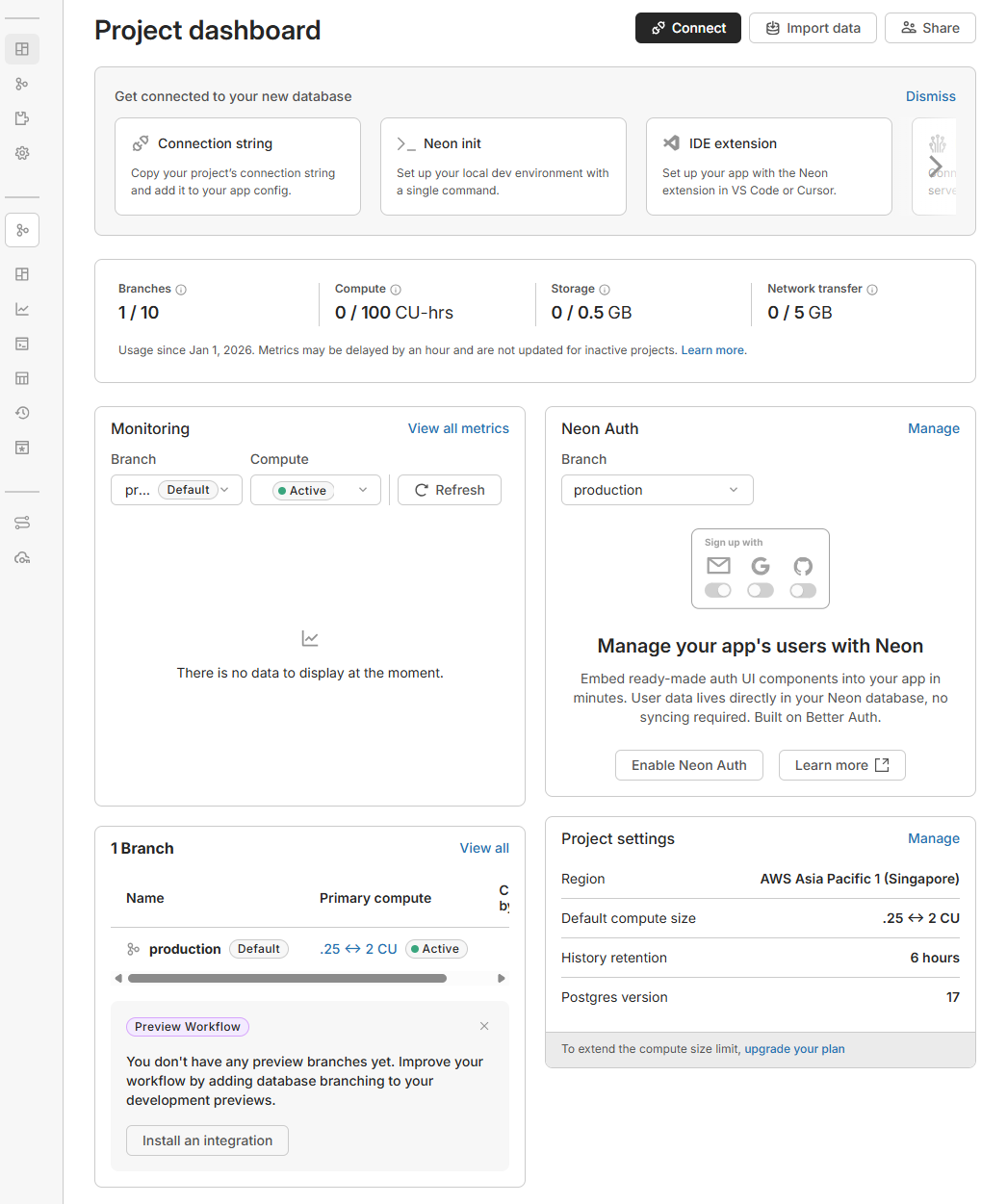
위의 화면에서 제일 중요한게 상단의 Connect를 누르게 되면 아래와 같은 커넥션 스트링이 뜨게 됩니다.
4-1.커넥션 스트링

위처럼 커넥션 스트링으로 dbms를 연결 또는 프로그램에서 입력해서 사용하면 됩니다.
또 기본 database 설정은 neondb로 되어있지만 이걸 다른 데이터베이스를 생성하여 변경해도 무방합니다.
4-2.오토스케일링 설정
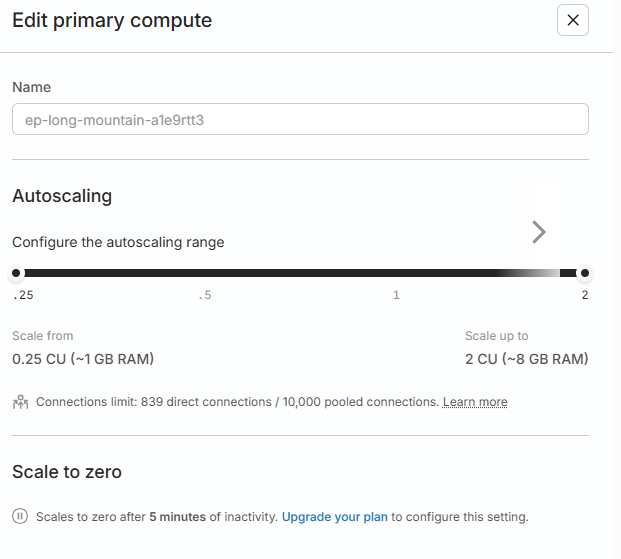
좌측하단의 브랜치의 priamry ocmpute를 클릭하게되면 아래와 같은 창이 뜨게 되는데 여기서 cu를 조절해서 오토스케일링 설정을 할수 있습니다.
클릭을 하면 아래와 같이 Autoscaling 설정 슬라이드가 우측에서 뜨게되는데 이때 최대치를 2로해두면 트래픽에 따라서 알아서 0.25~2CU까지 조절하면서 사용을 하게 됩니다.
5.Tables
NeonDB같은 경우에는 굳이 DBMS를 연결하지 않더라도 간단한 기능같은 경우에는 전부 웹 콘솔에서 실행하고 적용할수 있도록 해놨습니다. 좌측의 메뉴에서 Tables를 선택하면 아래와 같은 창이 뜨게 되는데 이때Database studio를 클릭합니다.

클릭을 하게 된다면 테이블을 생성하고 데이터베이스를 생성관리할수 있는 화면이 나타납니다.
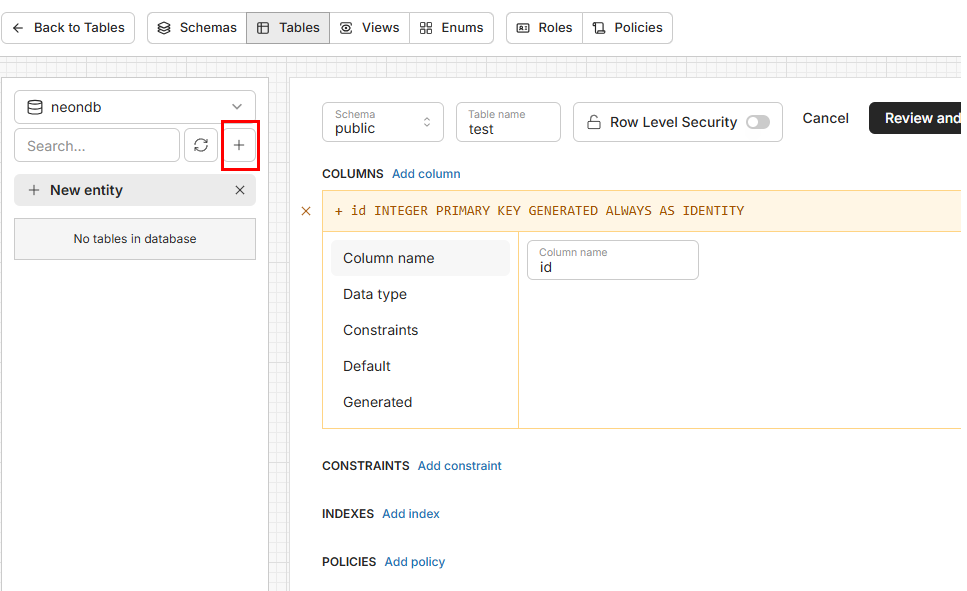

여기서 + 버튼을 눌러서 테이블을 생성하고 Review and create버튼을 눌러서 테이블을 생성해주면 좌측의 테이블리스트에 방금 제가 생성한 test가 뜨는것을 확인 할수있습니다.
6.SQL Editor
여기서 다시 좌측에서 sql editor를 누르면 쿼리를 입력할수 있는 창이 나오는데 별도의 dbms를 연결하지 않고도 이정도의 기능들을 웹에서 또 렉이나 시간지연없이 보여준다는게 놀랍습니다.
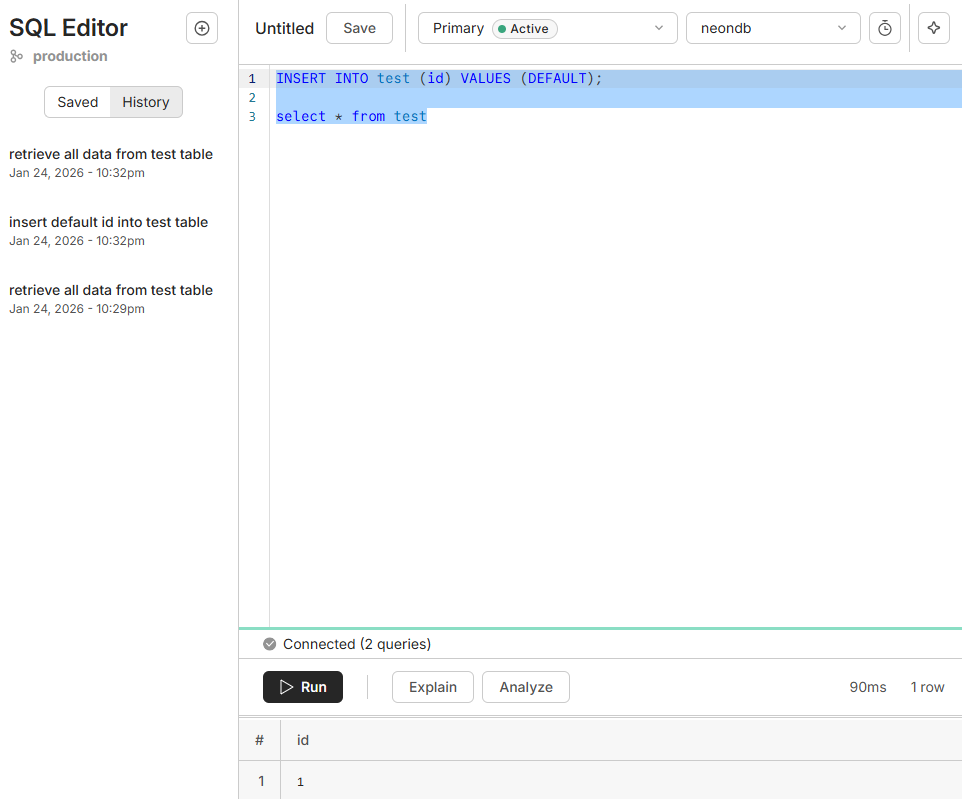
위처럼 쿼리를 치면 아래에 입력한 결과가 똑같이 출력 되는것을 확인할수 있습니다.
7.branch
그렇다면 NeonDB의 최대 장점 기능중 하나인 브랜치를 사용을 해보는데 이때 브랜치는 깃과 똑같이 메인브랜치에서 파생되는 브랜치를 똑같이 만들수 있으며 메인브랜치의 내용이 똑같이 파생브랜치에도 적용되게 됩니다.
좌측의 branch 메뉴를 클릭하고 우측상단의 New Branch버튼을 클릭해줍니다.
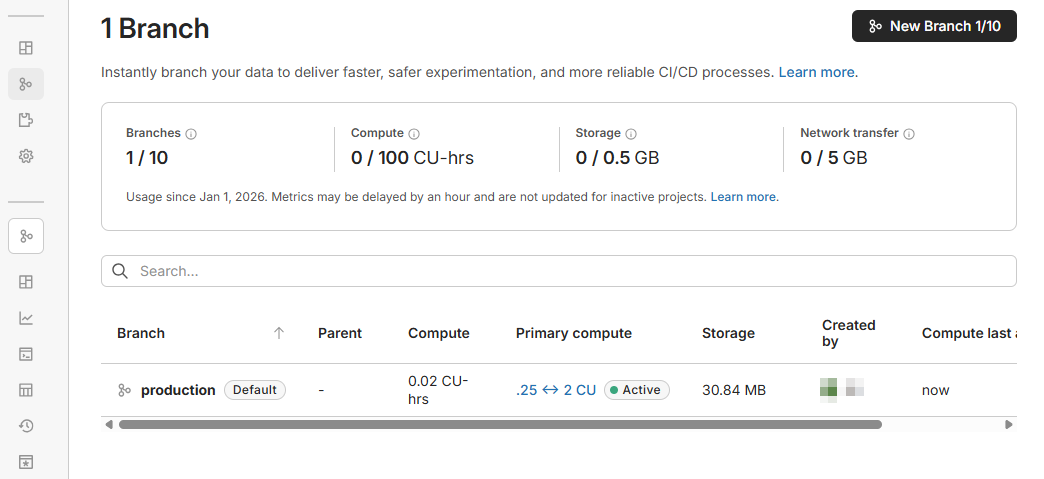
여기서 브랜치 이름을 설정해주고 automatically delete branch after 설정을 통해서 해당 브랜치를 몇일 동안 사용하지 않는다면 해당 브랜치를 삭제해주는 설정도 가능합니다.

여기서 각각의 설정의 의미는 아래와 같습니다.
1. Current data
의미: "지금 이 순간(Current)의 데이터를 그대로 가져와라."
결과: 운영 DB에 들어있는 회원 정보, 게시글 등 모든 데이터가 복제된 완벽한 쌍둥이 DB가 만들어집니다.
용도: 버그 재현, 새로운 기능 테스트 시 가장 많이 씁니다.
2. Past data (과거 시점 복구)
의미: "어제 오후 3시 시점의 데이터로 만들어라."
용도: 실수로 데이터를 지웠거나, 어제 발생한 버그를 잡기 위해 타임머신을 타고 싶을 때 씁니다.
3. Schema only (껍데기만 복사)
의미: "데이터는 필요 없고, 테이블 구조(Schema)만 가져와라."
결과: User, Post 테이블 등은 생성되지만, 데이터는 텅 비어 있습니다.
용도: 데이터 없이 깨끗한 환경에서 초기 개발을 하거나, 민감한 개인정보가 아예 없는 환경이 필요할 때 씁니다.
4. Anonymized data (가명 처리)
의미: "데이터를 가져오되, 이메일이나 이름 같은 건 가짜 데이터로 바꿔서 가져와라."
용도: 여러 개발자가 협업할 때, 실제 고객의 개인정보를 개발자들에게 노출하고 싶지 않을 때 씁니다. (아직 베타 기능)
여기서 1을 선택해서 현재의 브랜치와 똑같이 설정을 해보도록 하겠습니다.
8.branch 복사 확인
새롭게 만들어진 브랜치에 들어가서 확인을 해보면 아래와 같이 neondb에 만들었던 테이블인 test와 그 안에 있던 데이터 1이 있는것을 확인할수 있습니다.
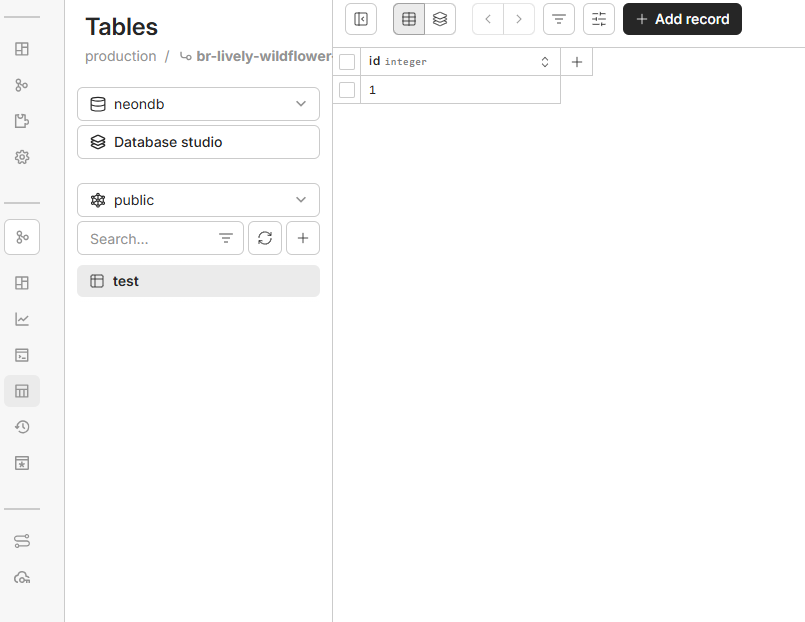
이처럼 네온db의 브랜치 기능을 사용한다면 여러 테스트 환경과 개발환경에서 알맞은 데이터 셋과 버젼을 만들고 그걸 지우고 관리하는 브랜치 버젼별로의 서버 운용과 서비스 운용이 매우 수월하게 가능해집니다.
마무리
지금까지 NeonDB의 핵심 기능과 사용법을 살펴봤습니다.
솔직히 처음 써봤을 때 가장 놀라웠던 건 솔직하게 "이게 정말 무료라고?" 싶은 압도적인 스펙이었습니다. 보통의 무료 티어 DB들이 일정 시간 지나면 꺼지거나(Heroku), 용량이 너무 작거나, 속도가 느려 터지는 답답함이 있었다면 NeonDB는 성능이슈도 없고 용량에 대한 문제도 없습니다.
특히 'Scale-to-Zero(자동 절전)', '브랜치(Branch)' 기능은 사이드 프로젝트를 운영하는 개발자한테는 매우 좋고 관리도 편한 기능입니다.
트래픽이 없을 땐 비용이 0원으로 수렴하고, 새로운 기능을 테스트할 땐 운영 DB를 건드릴 필요 없이 1초 만에 쌍둥이 DB를 만들어 마음껏 실험하고 지우면 되는 서비스입니다.
아직 한국에는 neondb가 유명하지 않은 것 같은데 본인이 무료 클라우드 db를 찾고 있고 나중에 스케일 업으로 점점 사이즈를 키울것이라고 하면 솔직히 복잡한 AWS RDS 설정과 요금 폭탄 걱정 할바엔, NeonDB를 사용하는것이 합리적이라고 생각합니다.
'Cloud' 카테고리의 다른 글
| 클라우드 서비스의 3대 핵심 모델 (IaaS, PaaS, SaaS 완벽 정리) (1) | 2025.12.15 |
|---|